by
using information provided by
This document describes the architecture of the Origin 2000 at the Center for Advanced Scientific Computing (CASC) at the University of Kansas starting with the smaller components and proceding to the overall system architecture. It then describes how users writin Fortran applications may exploit this architecture using compiler directives and shell commands provided by SGI. This tutorial is meant for users who wish to understand the basic operation of the Origin so they can write efficient parallel programs.
Two CPUs are connected through a "hub" to a memory to form a "node" and multiple nodes are connected using an interconnection network to form a complete Origin system. The distributed memories are seen as a single (logical) memory space, and any processor can access any memory location.
The Origin architecture is an instantiation of a Cache-Coherent Non-Uniform Memory Access (CC-NUMA) Architecture. The remainder of this document will:
The R1000 is 4-way superscalar; it can fetch and decode 4 instructions per cycle to be scheduled to run on its five independent, pipelined execution units:
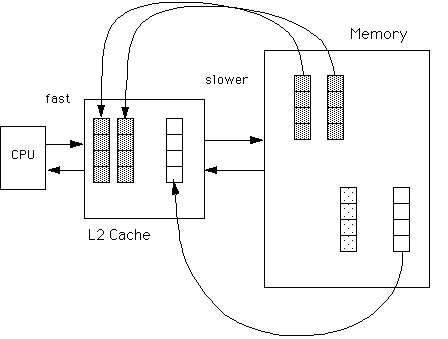
The R10000 is a cache-based RISC CPU, and programs must utilize cache well if they are to run efficiently on the Origin. The following diagram portrays a memory cache between a large main memory and its CPU.
The connection between the CPU and cache is very fast; the connection between the CPU and memory is slower. Memory is divided into groups of bytes called cachelines. In the drawing above each cacheline is represented by a stack of squares.
Bytes in a cacheline may comprise several variable values. Cachelines in memory are moved to cache for use by the CPU whenever the CPU needs one of the values stored in that cacheline. If a value is needed twice, or if another value in the same cacheline is needed, the the CPU can take the needed value directly from the cache (avoiding the delay associated with a memory access). (If a value in a cacheline is changed the cacheline must eventually be written back to memory.)
The R10000 actually utilizes a two-level cache hierarchy:
The R10000 can continue to execute instructions on up to 4 (L1 or L2) cache misses while waiting for operands to become available. That is, the CPU does not "block on a cache miss."
All work done before all preceding instructions have finished is considered temporary. If an exception is generated by an instruction that was postponed waiting for data, all temporary results can be undone and the processor state can be set to what it would have been had the instructions been executed sequentially. If no exceptions occur, an instruction executed out of order is "graduated" once all previous instructions have completed, and its result is added to the visible state of the processor.
Since the R10000:
Processor affinity is more complicated when multiple processes share data over multiple memories. Some methods of managing this complexity will be presented later.

The hub is basically a multi-port crossbar connecting the:
The memory system is interleaved on cache line addresses, and is fast enough that 4-way interleaving can feed the full memory bandwidth.
The Origin is built around a CrayLink router network, where each node can be connected to a CrayLink router and that router can be connected to other nodes or other routers or both. Here is a representation of a 2-node, 4-processor system using a single router:

The CASC Origin is an 8-node system with 16 processors occupying one cabinet. Each node is composed of 2 CPUs and 512MB memory. Each router has 6 ports and, as shown below, each router in the CASC Origin is connected to 2 nodes and 2 other routers in a level-2 hypercube (square) configuration (leaving 2 ports free on each router).
It is possible to construct "dense hypercube" routing networks (on Origin systems composed of fewer than 33 CPUs) by connecting hypercube vertices using an additional port on each router. These connections, called Xpress Links by SGI, are shown as dashed lines in the diagram below and have been installed in the Origin at KU.

The diagram below depicts a 32 processor Origin (16-node system). This system would fill two cabinets.

The following diagram shows two 16-node systems connected to form a 64-processor Origin.
It is possible to build systems of up to 64-nodes, 128-processors by
connecting 16-node systems to an external crossbar. (Not shown here.)
Consider the case represented in the diagram below.
Both CPUs have moved the light-colored cacheline into their caches.
If both CPUs do nothing but read values from that cacheline, they can
be assured that they hold the most recent values.
However, if one CPUs wishes to change a value in the cacheline, then
the other CPU should perform no further calculations using that cacheline
until it is updated.
This constraint is called "cache coherence" and can be enforced in
a variety of ways. For example:
Memory is organized into cache lines, and associated with
the databits in each cache line is:
Whenever a node requests a cache line, its hub initiates the
memory fetch of the whole line from the node that contains that line.
When the cache line is not owned exclusively, the line is fetched and
the state presence directory in the node that has the line is
modified. The bit whose number correlates with the number of the
calling node is set to 1.
As many bits can be set as there are nodes in the system. When a CPU wants to modify a cache line, it must gain exclusive ownership.
To do so, the hub retrieves the state presence bits for the target line
and sends an invalidation event to each node that has made a copy of the line.
Typically, invalidations need to be sent to only a small number of
other nodes; thus, the coherency traffic only grows proportionally
with the number of nodes, and there is sufficient bandwidth to allow
the system to scale.
The
executes program.exe and shows the following timings:
The command
The SGI "SpeedShop" is a suite of services that supports program tuning.
The command
Both
When a CPU executes a program it moves only the pages of the program
that contain instructions that are actually executed or pages that
contain data that is actually used to main memory.
In the drawing below, 2 pages from the executable image of Program 1 are
in memory, along with 1 page from the executable image of Program 2.
When there is no room for a new page, an old page is written back to
the paging disk (from which it may be read later), so that a new page
may be moved to memory. Some "page replacement algorithm" is used
to determine which page to return to disk. Typically, this process takes
place tens or hundreds of times a second in an active system.
Since the time required to read a page from disk is several orders of
magnitude longer than the time required to read a page from memory,
programs that minimize "page swapping" are generally much faster
than programs that do not.
In a distributed shared-memory, parallel environment virtual memory
is more complicated.
In general, a page will be moved from the paging disk to the node
containing the processor that requests the page.
Different pages from the same executable image may end up in
different nodes, as shown in the drawing below where Pages 1 and 2 from
the Program 1 executable image have been moved from the paging disk to
the memory in Node 1, but Page 3 has been moved to the memory
in Node 2.
Processes on either CPU may access data within any of the pages,
but there will be some delay when a process running on a CPU in one
node accesses data in a page stored in the memory of another node.
The delay will be the time required to transmit the requested page
over the internode network.
The hubs and interconnection fabric (CrayLink) have been designed to
simultaneously feed up to 2 processors operating at full speed.
If additional processors are requesting pages, there will be a
congestion delay added to the transmission delay.
It is this variability in the time required for a CPU to access
information in remote memories or caches on the Origin that makes it a
a "Non-Uniform Memory Access" (NUMA) architecture.
To minimize the time required to move a data from memory to a CPU,
the process using the page holding that data must be
running on a CPU as close as possible to the node containing that page,
and that node must be uncongested.
If requested by the user, IRIX can migrate pages among nodes
during execution to reduce access delays ("automatic migration"),
and users may explicitly control data and process placement using
various language and operating system features to be discussed later.
The following table shows some bandwidths and latencies for different
Origin topologies (195MHz systems only).

Cache Coherence
Multiprocessor systems whose CPUs are cache-based work more efficiently
when their CPUs can be certain that the values they take from their
caches are valid. That is, those cache values reflect the most recent values
assigned to individual variables.

Directory-based cache coherency
The Origin uses what is called a "directory-based" cache coherency
scheme.
Performance tuning tools
A significant part of parallel performance tuning
on the Origin platform is recognizing and eliminating cache usage problems.
SGI provides several tools that assist in this process (with both
scalar and parallel programs).
timex(1) command can be used to find out how much
time a program takes during execution. It reports both wall-clock and
CPU time (in both user and system modes of execution). During parallel
processing timex(1) reports the sum of CPU time used
by all processes in a "process share group". For example the command:
$ timex program.exe >output.txt
real 0m2.53s
user 0m11.53s
sys 0m0.12s
timex(1) information is very useful, but gives only
indirect information about some kinds of program behavior (e.g.,
cache and page use).
IRIX supports several commands for giving more direct information.
perfex(1) can be used to execute a program,
collect statistics during execution, and then display those
statistics for use in performance tuning.
In general, the information collected describes the activity of the
R10000 during execution, and, in specific, primary and secondary cache
activity is profiled.
The R10000 provides special counters within the chip to enable this
profiling activity.
ssrun(1) can be used to run an executable
image monitoring a collection of performance indicators, and
the prof(1) command can then be used to display the
collected information.
perfex(1) and ssrun(1) can provide
valuable information regarding cache and memory utilization.
To learn more about tuning cache usage on the Origin, see
Chapter 3: Single Processor Tuning in
Performance Tuning Optimization for Origin2000 and Onyx2.
Virtual memory in the distributed memory environment
Virtual memory is a technique used to improve the cost-efficiency of
main memory.
Program (executable) images are stored on paging disk when the are ready
to execute.
These images are stored in chunks of a specific size, called the "pagesize".
(16KB on the Origin 2000, though the R10000 can deal with other sizes).


Scalability: Latencies and Bandwidths
The speed with which a computer system can move data from memories to
CPUs will depend on the latencies and bandwidths of the connections among
the system components.
The scalability of a system depends on the degree to which bandwidth
is maintained and latency is minimized as a system grows.
Configurations
Link Bisection Bandwidths Router
hopsRead
LatencyNodes:CPUs Memory I/O Total per
Nodeper
CPUMax # Avg # Max ns Avg ns 1:2 .78 1.56 - - - - - 313 313 2:4 1.56 3.12 1.56 .78 .39 - - 497 405 4:8 3.12 6.24 3.12 .78 .39 1 .75 601 528 8:16 6.24 12.48 6.24 .78 .39 2 1.63 703 641 16:32 12.48 24.96 12.48 .78 .39 3 2.19 805 710 32:64 24.96 51.2 12.48 .39 .2 5 2.97 908 796 64:128 49.92 99.84 24.96 .39 .2 6 3.98 1112 903
The first column of the table shows the system configurations; these are categorized by the number of I/O crossbars (XBOWs), nodes and processors. The next two columns show the memory and I/O bandwidth for each of these configurations. Memory and I/O bandwidth scale linearly with the number of nodes.
The next three columns detail the bandwidths of the interconnection fabric. The basic unit of measure is the bisection bandwidth. This is a measure of the total amount of communication bandwidth the system supports. Due to the hypercube topology of the router configuration, it essentially scales linearly with the number of nodes.
The figures in this table reflect the use of Xpress Links for the 16- and 32-processor configurations.
The second and third bisection bandwidth columns show how the bisection bandwidth varies on a per-node and per-processor basis. An ideal communication infrastructure would allow constant bisection bandwidth per node or cpu.
The next two columns show the maximum and average number of router traversals for each configuration.
The final two columns show maximum and average read latencies. This latency is the time to access the critical word in a cache line read in from memory. The maximum latency grows approximately 100 nsec for each router hop. For the largest configuration, 128 processors, the average latency is no worse than on SGI Power Challenge systems, which employ a SMP bus architecture.
This information was taken from Chapter 1: Origin 2000 Architecture in Performance Tuning Optimization for Origin2000 and Onyx2 which includes more detailed scaling specifications.
-mp option as:
f77 -mp program.f
For example, loops preceded by the C$DOACROSS directive are broken into multiple loops, each one of which performs a section of the iteration range. The following loop:
c$doacross mp_schedtype=simple,local(i),shared(A,B,C)
do i = 1,1000
C(i) = A(i) * B(i)
end do
will be executed on 4 processors as the following 4 loops:
do i = 1,250 C(i) = A(i) * B(i) end do
do i = 251,500 C(i) = A(i) * B(i) end do
do i = 501,750 C(i) = A(i) * B(i) end do
do i = 751,1000 C(i) = A(i) * B(i) end do
These separate processes, sometimes called "threads," are started
simultaneously, share the same memory image, and
have the same process group (pgrp) ID.
Each thread will work on its own private, "local," version of
the iteration variable i.
Each thread will share the arrays A, B, and C, but
since they will operate on different locations within those arrays,
they will not logically interfere with each other's work.
(They may affect one another's performance, however, as we will see later.)
When a thread has completed its work, it will "busy-wait" until
all threads have completed their work. Threads in busy-wait will
show 100% CPU utilization on CPU utilization displays
(like top(1), even though they are doing no useful work.
There are different ways to break a loop into multiple processes:
Here is a list of parallelization directives inherited from the Power Challenge, and still recognized on the Origin. The compiler directives look like Fortran comments; they begin with a C in column one. If multiprocessing is not turned on, these statements are treated as comments. The directives are distinguished by having a $ as the second character.
You can invoke the Power Fortran Analyzer by using the -pfa
option with the f77(1) command.
The resulting Fortran program can be compiled and executed following
analysis, or examined for guidance when parallelizing a program by hand.
For more information about the Power Fortran Analyzer, see the MIPSpro Power Fortran 77 Programmer's Guide.
First-touch page placement is often quite efficient. However, there are many cases where it produces non-optimal page placement leading to inefficient program execution.
For example, suppose the variable C in the previous example, had been initialized in a non-parallel loop, so that all the pages containing C were placed in the same memory. Executing the previous loop in parallel would then necessitate considerable internode traffic as pages of C were moved to other nodes for execution.
To deal with this problem, the parallel languages supported by IRIX include directives for (explicitly) controlling the placement of data among Origin nodes.
For example, the following code fragment:
c$distribute C(block)
c$doacross mp_schedtype=simple,local(i),shared(A,B,C)
do i = 1, N
C(i) = A(i) * B(i)
end do
employs the c$doacross directive to tell the compiler to
break array C into blocks of size N/P, where P is
the number of processes the loop is broken into. If the array C is defined
for index values from 1 to N, for example, it will be distributed
among 4 processors approximately as follows:
Exact placement is adjusted so that page boundaries are not crossed.
SGI provides the following directives for data placement:
The parameter <dist> specifies how to partition the values in one array dimension, and can be one of:
It is possible, however, to coordinate the distribution of data with the assigment of processors to work on that data. For example, in the following code fragment:
c$distribute C(block)
c$doacross local(i),shared(A,B,C),affinity(i) = data(A(i))
do i = 1,100000
C(i) = A(i) * B(i)
end do
array C will be distributed among multiple nodes in blocks (respecting page boundaries), and individual iterations of the loop will be executed on processors connected to the node that contains the value of C referenced in the loop.
SGI provides the following directives for coordinating thread and data location:
The data distribution directives and doacross nest directive have an optional ONTO clause to control the partitioning of processors across data in multiple dimensions.
For instance, if an array is distributed in two dimensions, you can use the ONTO clause to specify how to partition the processors across the distributed dimensions.
For more information about data placement using Fortran77 see Chapter 6: Parallel Programming on Origin 2000 in the MIPSpro Fortran77 Programmer's Guide.
For more information about the design of the page placement constructs within IRIX, see Data Distribution Support on Distributed Shared Memory Multiprocessors.
dplace(1) can be used to guide placement
at runtime from the command prompt.
If you have compiled a program called program.f, and created an
executable called program.exe, you can use dplace to run it
as 2 threads on two separate nodes by using a command like:
dplace -place placement_file program.exe
where placement_file contains:
memories 2 in topology cube # set up parallel sections to
threads 2 # run as 2 threads in 2
# different nodes (memories)
# arranged as the corners of
# a hypercube.
run thread 0 on memory 1 # run the first thread on the
# second node.
run thread 1 on memory 0 # run the second thread on the
# first node.
Note that page placement using this placement file will be determined by first-touch allocation, since the placement file does not specifiy exact data placement.
The library routine dplace(3) can be used to specify a
placement file at runtime through a library routine call.
For more info about placement using dplace see dplace(1),
dplace(3), and dplace(5).
dprof(1) allows users to obtain a map of memory
use by a program. For example, the executable image on program.exe could
be profiled by using a line like
dprof -out memory-map program.exe
where the memory map will be stored on the file memory-map.
dlook facility for
examining process and memory distribution across the Origin. This
is probably an IRIX 6.5 feature.
For more guidance in using the parallel features of the Origin, see Chapter 4: Multiprocessor Programming in Performance Tuning Optimization for Origin2000 and Onyx2 .
For example, programmers must take care to avoid activities that induce:
In general, all of these activities can degrade program performance, and in some cases, you must balance them off against one another.
There are several ways to evaluate the effectiveness of parallelization strategies. One of the most straightforward is to compare the wall-clock times required to solve a particular problem in both scalar and parallel modes running on an otherwise empty system. This gives you the "speed-up" factor due from parallel processing.
However, it is also useful to compare the CPU used in both scalar and parallel modes, so you can estimate the efficiency with which the parallel process uses CPU resources. That is, how much CPU time is used to achieve the observed wall-clock speedup? Ideally, the parallel process would use no more CPU time than the scalar process, but usually the parallel process will utilize more resources, and, occasionally, the parallel process will consume significantly more CPU time, leading to overall waste of system resources.